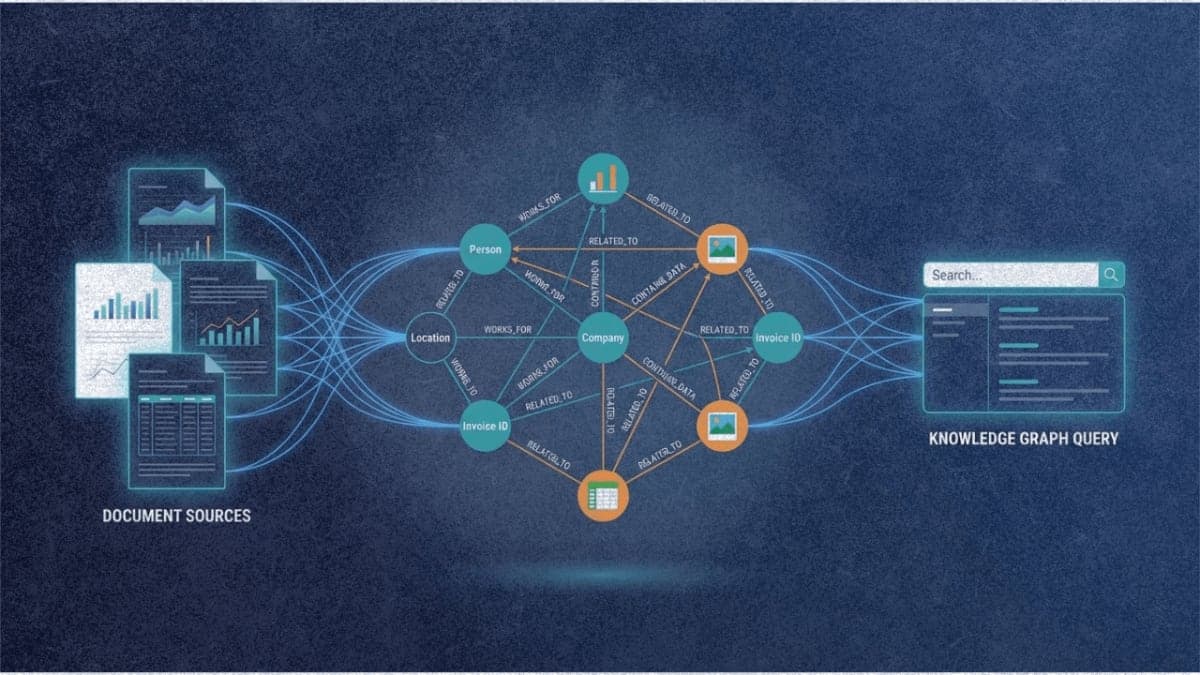
A team of researchers from National Taiwan University and E.SUN Financial Holding has developed MegaRAG, a retrieval-augmented generation system that automatically builds knowledge graphs from documents containing figures, charts, and tables. The approach addresses a persistent weakness in existing graph-based RAG methods: they extract entities and relationships from text alone, ignoring the visual elements that often carry critical information in real-world documents.
The problem with text-only graphs
GraphRAG, the Microsoft-developed system that popularized knowledge graph construction for RAG, works by prompting LLMs to extract entities and relationships from text chunks, then clustering related nodes into communities for hierarchical summarization. LightRAG later improved on this with more efficient retrieval. Both systems treat documents as pure text, which creates obvious gaps when processing slide decks, textbooks with diagrams, or corporate reports heavy on charts.
MegaRAG takes a different approach by feeding page images, extracted figures, and tables directly into multimodal LLMs alongside the text content. The system treats each meaningful visual element as a potential entity node, connecting it to textual entities when relationships exist. A bar chart titled "Monthly Website Visitors" gets linked to surrounding text about user engagement trends, for instance.
Two-round graph construction
The paper describes a page-based pipeline that runs in two passes. The first round extracts entities and relations from each page independently using GPT-4o-mini with multimodal inputs. Page-level graphs are then merged by aligning nodes with matching names.
The second round is where things get interesting. Rather than relying on additional extraction from scratch, MegaRAG retrieves a subgraph from the initial knowledge graph for each page and uses it as context for refinement. This lets the MLLM identify cross-page relationships and text-to-figure connections that were missed in isolation. The researchers avoided feeding the entire graph into the context window, which would have been prohibitively expensive. Instead, they retrieve the 120 most relevant entities and relations per page.
For retrieval, MegaRAG uses GME-Qwen2-VL-2B, an embedding model from Alibaba's Tongyi Lab that encodes text, images, and text-image pairs into a unified vector space. This enables the system to handle queries that might need text-to-text, text-to-image, or mixed-modality retrieval.
Performance on visual documents
The researchers tested MegaRAG against GraphRAG, LightRAG, and standard chunk-based RAG on both text-only and multimodal benchmarks. On the UltraDomain dataset of college textbooks (purely textual), MegaRAG achieved win rates averaging 71.8% overall against baselines in LLM-based pairwise comparisons.
The gaps widened considerably on multimodal documents. Testing on lecture slide decks, corporate sustainability reports, and a world history textbook, MegaRAG achieved 89.5% overall win rates. On a Chinese-language generative AI lecture deck, it won 99.2% of comparisons against GraphRAG, which could only process the extracted text and missed the visual content entirely.
The local question-answering results were more concrete. On SlideVQA, a benchmark requiring reasoning over educational slides, MegaRAG hit 64.85% accuracy versus 27.66% for LightRAG and 6.8% for GraphRAG's local search mode. The RealMMBench results showed similar patterns, with MegaRAG reaching 58-61% accuracy on slide-based subsets where baselines struggled to break 35%.
What the ablation reveals
The most telling result from the ablation study: removing MMKG-based retrieval and relying only on page retrieval caused performance to collapse to near-zero win rates. This suggests the structured graph representation is doing significant work beyond what similarity-based page retrieval can achieve.
Removing visual inputs from graph construction was less catastrophic but still damaging, dropping overall win rates by roughly 25-30 percentage points on slide-heavy datasets. The two-stage answer generation, which separately reasons over the knowledge graph and visual content before combining results, contributed more modest gains of 14-25 percentage points.
The multimodal RAG landscape
MegaRAG enters a space that's getting crowded. In the past few months, multiple research groups have proposed variations on multimodal knowledge graph RAG. mKG-RAG from a different team focuses on visual question answering with manually curated multimodal knowledge graphs. M3KG-RAG tackles audio-visual reasoning with multi-hop graph construction. MMGraphRAG uses scene graphs combined with text-based knowledge graphs.
What distinguishes MegaRAG is the automatic construction pipeline. Prior work on multimodal knowledge graphs for RAG typically required human-curated graph structures or focused on specific domains. MegaRAG's pipeline runs without fine-tuning and handles arbitrary visual documents by leveraging off-the-shelf MLLMs and embedding models.
The practical limitations are real. Graph construction requires two passes through every page with GPT-4o-mini, which adds up for large document collections. The GME embedding model runs on local GPUs with roughly one second per page image. The researchers used the MinerU toolkit for document parsing, which handles PDFs reasonably well but still struggles with complex layouts.
What comes next
The system requires GPT-4o-mini for graph construction and answer generation, tying it to OpenAI's API. A fully local implementation would need open-source MLLMs capable of similar extraction quality, which remains a gap in the current ecosystem.
The research team has released code on GitHub, though adoption will likely depend on whether the performance gains justify the added complexity over simpler multimodal RAG approaches like VisRAG, which skips graph construction entirely and retrieves document images directly.
For organizations dealing with visual-heavy document collections where text extraction loses critical information, MegaRAG presents a concrete alternative. The question is whether the structured reasoning benefits of knowledge graphs outweigh the pipeline complexity for any given use case.



