Nvidia researchers published a paper on January 12th describing KVzap, a method for compressing the KV cache in transformer models by 2-4x. The approach trains a tiny surrogate model to predict which key-value pairs can be safely discarded. Compute overhead is 0.02% for the linear variant.
The problem everyone's stuck on
KV cache is the memory bottleneck nobody's solved cleanly. Every token you process gets stored as key-value pairs for every layer and every attention head. For a 65B parameter model at 128k context, that's around 335 GB of memory just for the cache. Not weights. Just the cache.
Most compression methods go after the wrong axes. Grouped Query Attention, which you see in Llama 3 and Qwen, compresses along the head dimension. DeepSeek's Multi-head Latent Attention compresses the key/value dimensions. Both help, but the real redundancy is in the token axis. Not all 128,000 tokens matter equally for what comes next.
KVzip had the right idea
The original KVzip from Seoul National University figured this out. Their insight: prompt the model to "repeat the previous context" using only the compressed cache. If reconstruction works, the compression was lossless. Tokens that barely affect reconstruction can be evicted.
It worked. 3-4x compression with minimal quality loss on QA, retrieval, reasoning tasks. But there's a catch buried in the details: you basically run prefill twice. The compression step uses the same model to evaluate importance, which means you're doubling your compute at the expensive prefill stage. For single-query scenarios that might be fine. For production workloads where you're processing prompts constantly, that's painful.
What Nvidia actually did
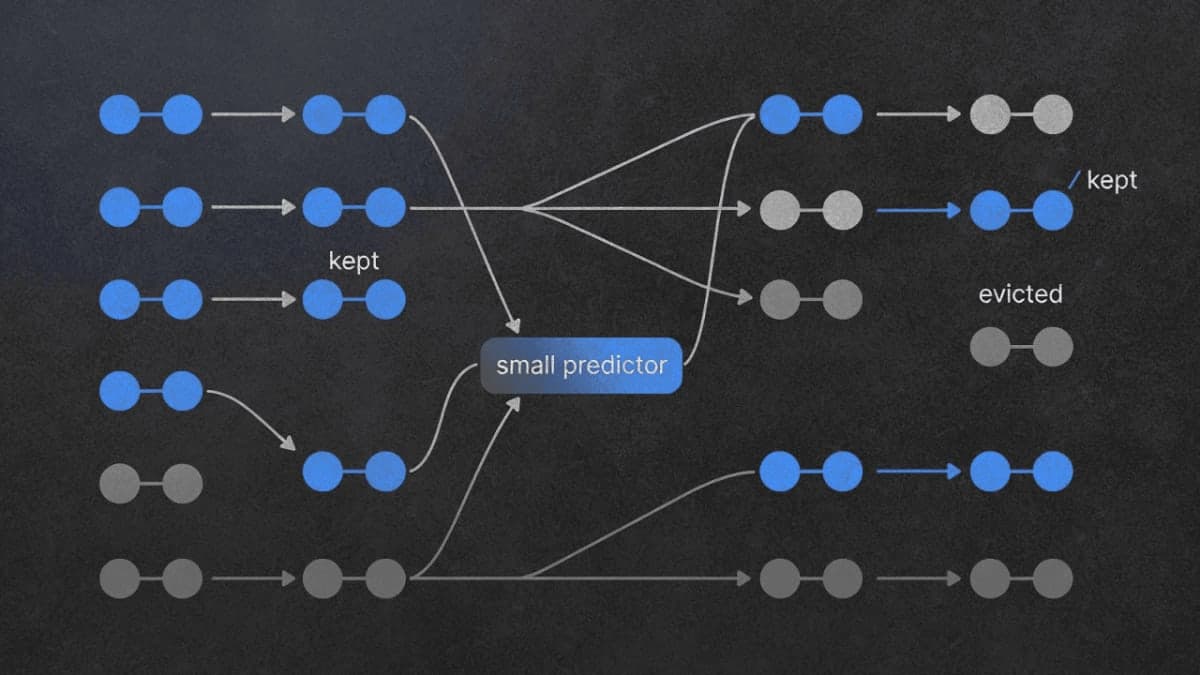
KVzap sidesteps the expensive reconstruction step entirely. Instead of running the full model to score token importance, they train a tiny predictor that looks at each token's hidden state and outputs an importance score.
How tiny? Either a single linear layer or a two-layer MLP, trained separately for each transformer layer. The linear version adds 0.02% FLOPs. The MLP version is around 1.1%. Both are noise compared to the quadratic attention cost at long contexts.
Training data comes from Nemotron's pretraining dataset with English, code, and multilingual text. They generate labels by running the full KVzip scoring procedure offline, then distill those scores into the lightweight predictor.
The other change: thresholding instead of fixed budgets. KVzip says "keep exactly 50% of tokens." KVzap says "keep everything above importance score τ." This makes compression adaptive. Dense, information-rich prompts keep more tokens. Redundant prompts get compressed harder. Makes intuitive sense, though I'd want to see how often the adaptive rate lands way off target in practice.
Does it actually work
On the KVpress leaderboard, KVzap matches or beats 15 other methods on both Qwen3-8B and Llama-3.1-8B-Instruct. The RULER benchmark at 4k tokens shows it essentially tracking KVzip's performance curve while everything else falls behind.
They tested up to Qwen3-32B on RULER (synthetic long-context tasks) and LongBench (real documents). Also AIME25, which is 30 math olympiad problems. Results hold across all of them.
But here's what I couldn't find: scaling behavior beyond 32B. The paper tests up to 32B parameters and 128k tokens. Production models like DeepSeek-V3 are 671B parameters. Does the surrogate approach still work when the base model is 20x larger? The paper doesn't say.
The threshold problem
Choosing τ isn't trivial. Too high and you evict important tokens. Too low and you don't compress much. The paper shows different thresholds yielding different compression ratios, but doesn't give clear guidance on how to set τ for a new model or task.
The code is up and integrates with their kvpress library. You can specify threshold=-4 and get... some compression ratio that depends on your input. This is probably fine for research but feels like it needs more tooling for production use.
What matters here
The interesting bit isn't the compression ratio. Other methods get similar numbers. It's the overhead. At 0.02% additional FLOPs, you can turn this on without thinking about it. The decision becomes "do I have memory pressure?" rather than "is the compression benefit worth the compute cost?"
For inference servers running long-context workloads, that changes the calculus. You're not trading latency for memory anymore. You're just getting free memory back.
Whether the surrogate training generalizes to models not in their test set is an open question. And whether the threshold-based approach causes problems on edge cases, also unclear. But as a starting point for practical KV cache compression, this looks more deployable than anything I've seen before.
Code's MIT licensed if you want to try it.