QUICK INFO
| Difficulty | Intermediate |
| Time Required | 45-60 minutes |
| Prerequisites | Built at least one working AI agent, familiarity with async JavaScript or Python |
| Tools Needed | Node.js 18+ or Python 3.9+, API access to an LLM (Claude, GPT-4, etc.) |
What You'll Learn:
- Choose the right orchestration pattern for your coordination needs
- Implement shared state vs. message passing between agents
- Handle token economics without surprise bills
- Debug multi-agent failures before they cascade
Single agents hit walls fast. Context windows fill up, decision trees get tangled, and debugging a 50-step reasoning chain is nobody's idea of a good time. Multi-agent systems split the work across specialized agents, each doing one thing well. The catch: now you need those agents to coordinate, which introduces its own failure modes.
This guide covers the three orchestration patterns that matter, when to use each, and production lessons from systems running under real load. You should already have a working single agent before reading this.
Why You'd Want Multiple Agents
The honest answer: you probably don't, at first. Single agents handle most tasks fine. But you hit limits when tasks need genuine specialization (financial analysis vs. code generation), parallel processing (four data sources at once), or maintainability (knowing which component broke).
The tradeoff nobody mentions upfront: coordination overhead. Agents communicating, sharing state, avoiding conflicts. Get the coordination wrong and you've built a more expensive way to fail.
The Three Orchestration Patterns
Three patterns cover most real deployments. Pick based on coordination requirements, not what sounds sophisticated.
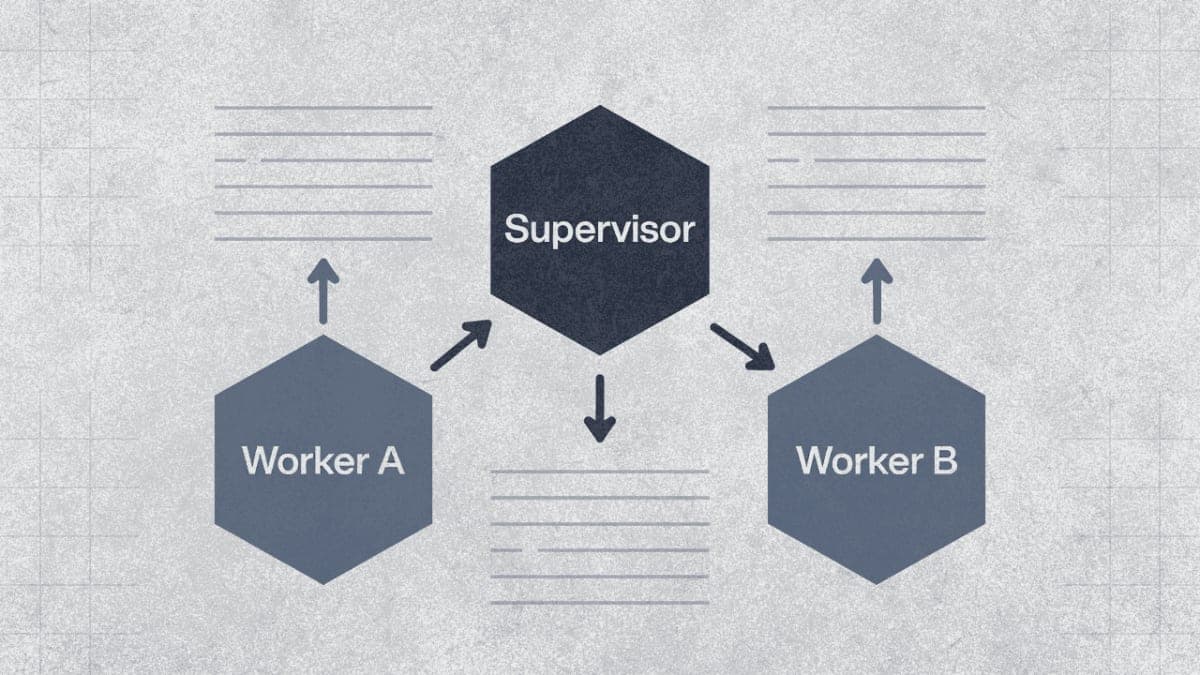
Supervisor Pattern
A central supervisor agent receives tasks, breaks them into subtasks, routes work to specialized workers, validates outputs, and synthesizes the final response.
User Request
↓
[Supervisor Agent]
↓
Decompose → Route → Monitor → Validate → Synthesize
↓ ↓ ↓
[Worker 1] [Worker 2] [Worker 3]
The supervisor handles strategy. Workers handle execution. In practice, this looks like four financial analysts running in parallel while a coordinator synthesizes their findings:
// Supervisor coordinates parallel analysis
const analyses = await Promise.all([
fundamentalAgent.analyze(ticker),
portfolioAgent.analyze(ticker),
riskAgent.analyze(ticker),
technicalAgent.analyze(ticker)
]);
// Supervisor synthesizes results
const report = await supervisorAgent.synthesize(analyses);
The problem with supervisor patterns is bottlenecking. Every coordination decision routes through one agent. Token costs scale with coordination layers since you're paying for the supervisor's reasoning on top of worker outputs.
Use supervisor when you need auditability and clear task decomposition. Works well up to about 8 workers before coordination overhead dominates.
Swarm Pattern
No central controller. Agents communicate directly, exchange information, and self-organize. Think ant colonies rather than org charts.
[Agent A] ←→ [Agent B]
↕ ↘ ↙ ↕
[Agent C] ←→ [Agent D]
Each agent can talk to any other agent. Information flows through the network until the task completes or consensus emerges. A travel planning system might have six agents (destination, flights, hotels, dining, itinerary, budget) reading and writing to shared state:
class TravelState {
destination: string;
flightOptions: Flight[];
hotelOptions: Hotel[];
budget: BudgetConstraints;
}
// Each agent reads shared state, does its work, updates state
await destinationAgent.explore(state);
await flightAgent.search(state); // Uses destination from previous
await hotelAgent.search(state); // Uses destination and dates
Swarms are hard to debug. Without a coordinator, you're tracing information flow through a mesh, not a tree. Agents might duplicate work or create loops. I'd avoid this pattern unless you specifically need multiple perspectives converging without clear task decomposition.
Hierarchical Pattern
Supervisor pattern, but recursive. Top-level agent manages mid-level agents, which manage workers. Three or more layers.
[Top-Level Supervisor]
↓
┌─────────┴─────────┐
↓ ↓
[Mid-Level A] [Mid-Level B]
↓ ↓
[Workers 1-3] [Workers 4-6]
A documentation generator might have a top-level orchestrator delegating to an analysis team, a documentation team, and a validation team, each with their own specialized workers.
The problem: token costs explode. A three-layer hierarchy with 5 agents per layer burns 50K+ tokens on coordination alone. Only justified when flat patterns genuinely can't handle the complexity.
How Agents Actually Communicate
Patterns tell you structure. Communication strategies tell you how information moves.
Shared State
All agents read from and write to a common state object. Changes are visible to everyone.
interface SharedState {
task: string;
results: Map<string, any>;
currentStep: string;
}
// Agent A writes
state.results.set('analysis', analysisResult);
// Agent B reads
const analysis = state.results.get('analysis');
Start here. Simple to implement, easy to debug (just inspect state), no message infrastructure needed. Race conditions can bite you if agents write simultaneously, and state grows unbounded without pruning. But most agent systems should use shared state until they hit specific problems it can't solve.
Message Passing
Agents send messages through an event bus. No direct state sharing.
eventBus.publish('analysis.complete', {
ticker: 'AAPL',
analysis: result
});
eventBus.subscribe('analysis.complete', async (event) => {
await portfolioAgent.process(event.analysis);
});
Loose coupling between agents, natural for async work, easy to add new agents. Harder to debug since you're tracing message flow. Use this when agents are truly independent and shouldn't know about each other.
Handoff Mechanism
One agent explicitly passes control to another with context.
class Agent {
async handoff(targetAgent: Agent, context: Context) {
const handoffContext = {
previousAgent: this.name,
taskContext: context,
timestamp: Date.now()
};
return await targetAgent.execute(handoffContext);
}
}
Clear control flow and easy to audit, but tight coupling and serial by default. Use when tasks must happen in specific order.
Memory Architecture
Single agents use context windows and external memory. Multi-agent systems add another problem: coordinating state without duplicating it or creating conflicts.
Session-based memory gives each agent interaction an isolated session that merges back to shared memory on completion. Common in supervisor patterns where workers operate independently.
Window memory keeps a sliding window of recent exchanges across all agents, compressing or dropping oldest entries. Works for long-running conversations where you can't keep everything but context matters.
I haven't tested episodic memory (storing interaction history between specific agent pairs) in production enough to say whether it's worth the complexity.
Production Realities
Lab demos scale differently than production.
Token Economics
Multi-agent systems burn tokens fast. Four agents coordinating can easily 10x costs versus a single agent.
Typical supervisor system breakdown:
- Supervisor decomposition: ~1K tokens
- 4 worker agents at 3K each: 12K tokens
- Supervisor synthesis: ~2K tokens
- Total: ~15K tokens
Compare to a single agent doing the same task: maybe 4K tokens. You're paying for coordination.
Cache supervisor instructions when possible. Compress worker outputs (structured data, not prose). Always parallelize independent work.
Latency
Each LLM call adds 2-5 seconds. Serial processing kills user experience.
- 1 agent: 3 seconds
- 4 agents serial: 12 seconds
- 4 agents parallel: 3-4 seconds
Always parallelize independent work.
Error Propagation
One agent returning garbage can break downstream agents. Circular dependencies create deadlocks. Parallel agents hammering the same rate-limited API exhaust resources.
Defenses: timeouts at every layer, circuit breakers after N failures, graceful degradation with subset of agents, isolated state so worker failures don't corrupt shared state.
Monitoring
You can't debug what you can't see. Track per-agent success rate, coordination overhead, token consumption by agent, and interaction patterns.
class ObservableAgent {
async execute(task: Task): Result {
const span = tracer.startSpan('agent.execute', {
agentId: this.id,
taskType: task.type
});
try {
const result = await this.process(task);
span.setStatus({ code: SpanStatusCode.OK });
return result;
} catch (error) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: error.message
});
throw error;
} finally {
span.end();
}
}
}
Troubleshooting
Symptom: Agents produce conflicting outputs Fix: Check if agents are reading stale state. Add timestamps to state updates. Consider sequential execution for interdependent agents.
Symptom: Token costs spike unexpectedly Fix: Log token usage per agent per task. Usually one agent is being too verbose in its reasoning. Constrain output format.
Symptom: Supervisor bottleneck under load Fix: Batch similar tasks for single decomposition. Cache routing decisions. Consider swarm pattern if tasks are truly independent.
Symptom: Circular agent calls Fix: Add call depth limits. Log agent invocation chains. Usually a sign your task decomposition is wrong.
Choosing Your Pattern
Use Supervisor when: Tasks decompose clearly, you need auditability, 3-8 specialized agents, quality matters more than speed.
Use Swarm when: Multiple perspectives needed, no clear decomposition, real-time responsiveness critical. (Actually, reconsider whether you need multiple agents at all.)
Use Hierarchical when: Managing 10+ agents, multiple abstraction layers, token costs are acceptable.
Use single agent when: Task is simple enough, one domain sufficient, minimizing costs matters, you're not sure yet.
What's Next
Build one system with two agents before building ten. Start with supervisor pattern, add one worker, observe coordination overhead, iterate.
The motia-examples repository has production implementations worth studying, including a chess arena (competitive multi-agent), finance agent (supervisor pattern), and travel planner (shared state coordination).
PRO TIPS
Parallel execution saves more time than any optimization. Four agents at 3 seconds each running parallel beats one agent at 10 seconds every time.
Structured output from workers reduces synthesis cost. Don't have workers return prose the supervisor must parse. Return JSON the supervisor can merge.
Start with shared state, move to message passing only when you hit specific problems shared state can't solve.
Log everything the first week. Token counts, latencies, error rates per agent. You'll find your bottleneck fast.
FAQ
Q: How many agents before I need hierarchical pattern? A: Usually around 10 workers. Below that, flat supervisor handles coordination fine. Above that, mid-level coordinators start paying for themselves.
Q: Can I mix patterns in one system? A: Yes. A supervisor can coordinate workers that internally use swarm communication. Just be aware of the complexity you're adding.
Q: What's the minimum viable multi-agent system? A: Two agents with shared state. One does retrieval, one does synthesis. That's it. Prove value before adding complexity.
Q: How do I handle agent failures gracefully? A: Timeouts on every agent call, fallback responses from cached results, and degraded mode that works with subset of agents. Design for partial failure from day one.
RESOURCES
- motia-examples repository: Production multi-agent implementations
- OpenAI Multi-Agent Cookbook: Patterns and code samples
- LangGraph Documentation: Framework for building agent graphs