
MiniMax, the Shanghai-based AI company behind the Hailuo video generator, has released VTP (Visual Tokenizer Pre-training), a framework that claims to solve one of latent diffusion's most stubborn problems: the tokenizer doesn't scale. The paper dropped on arXiv December 15th, and the weights are already on Hugging Face under MIT license.
The problem nobody wanted to admit
Here's the dirty secret of latent diffusion: throw more compute at your VAE and you'll get better reconstruction, but your generated images won't improve. They might actually get worse. The HUST Vision Lab (who collaborated with MiniMax on this work) documented this "optimization dilemma" earlier this year in their VA-VAE paper, showing that higher-dimensional tokenizers produce better reconstructions but require substantially larger diffusion models to achieve comparable generation quality.
The conventional wisdom has been to just accept it. Train your VAE once, freeze it, and focus your scaling budget on the DiT. But MiniMax argues this is solving the wrong problem. The issue isn't that VAEs can't be scaled, it's that reconstruction-only training produces a latent space that's biased toward low-level pixel information. And low-level information, as it turns out, is exactly what diffusion models struggle to learn efficiently.
What VTP actually does
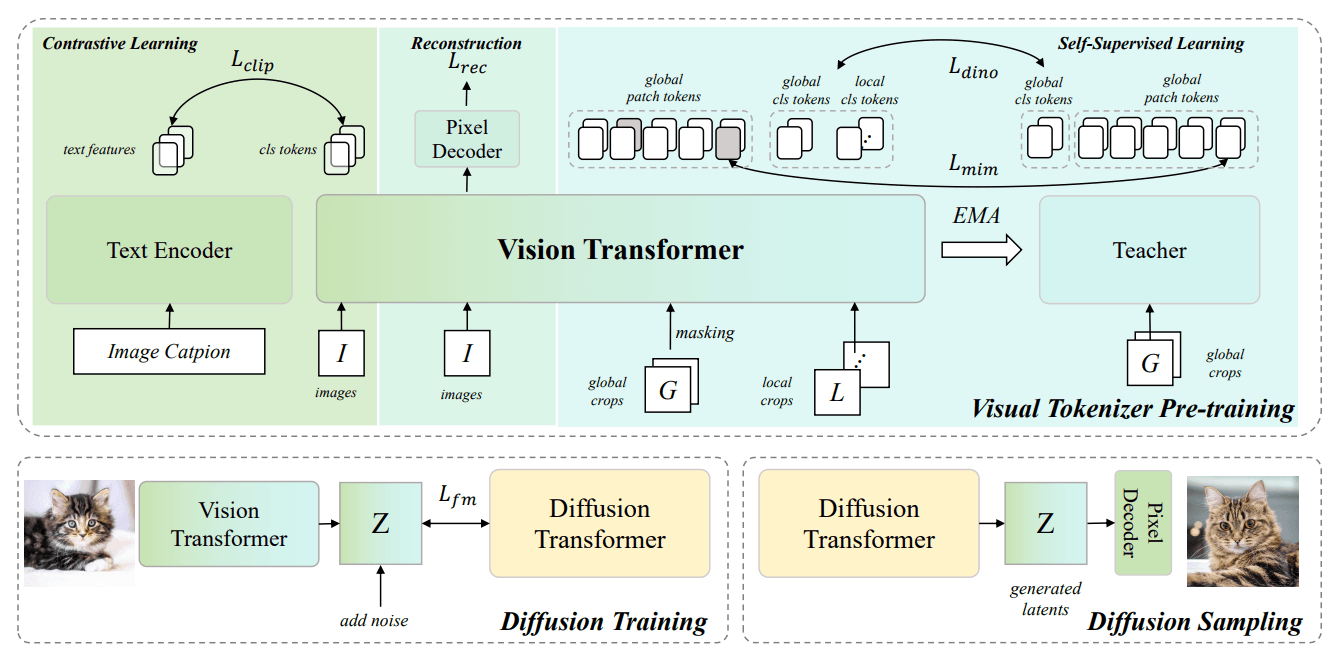 VTP's approach is conceptually simple: train the tokenizer on multiple objectives simultaneously. Alongside the standard pixel reconstruction loss, they add image-text contrastive learning (the CLIP approach) and self-supervised learning through masked image modeling and self-distillation (the DINOv2 approach). The encoder is a Vision Transformer rather than the traditional CNN used in most VAEs.
VTP's approach is conceptually simple: train the tokenizer on multiple objectives simultaneously. Alongside the standard pixel reconstruction loss, they add image-text contrastive learning (the CLIP approach) and self-supervised learning through masked image modeling and self-distillation (the DINOv2 approach). The encoder is a Vision Transformer rather than the traditional CNN used in most VAEs.
The combination forces the latent space to encode semantic information, not just pixel correlations. MiniMax's experiments show a strong positive correlation between the semantic quality of the latent space, measured via zero-shot classification accuracy, and generation performance measured via FID. Their largest model achieves 78.2% zero-shot accuracy on ImageNet alongside a 0.36 rFID, which puts it in respectable territory against dedicated representation learning models.
The generation improvements are where things get interesting. Without changing anything about the DiT training configuration, VTP claims a 65.8% FID improvement over baseline tokenizers. Convergence speed increases by roughly 4x compared to VA-VAE, which itself was already faster than standard approaches.
The scaling question
What MiniMax really wants you to pay attention to is Figure 7 in their paper. Traditional autoencoders hit a performance plateau almost immediately when you scale up pre-training compute. The line essentially flatlines after 1/10th of the compute budget they tested. VTP keeps improving even at 10x that scale.
This is the core claim: VTP is "the first visual tokenizer to demonstrate scaling properties" for downstream generation. It's a bold statement, and the supporting data is limited to their own experiments. The benchmarks are ImageNet 256x256, which is the standard testing ground but hardly representative of real-world generation tasks. Whether these gains hold for text-to-image at higher resolutions, or for video generation where MiniMax has commercial interests, remains unverified.
The three released checkpoints range from 200M to 700M parameters, substantial for a tokenizer but small by foundation model standards. VTP-Large sits at 0.7B parameters, VTP-Base at 0.3B, and VTP-Small at 0.2B. All use a 16x spatial downsampling factor with 64-dimensional latents, matching the standard configuration used in most latent diffusion systems.
Why this matters for MiniMax
MiniMax isn't releasing this out of pure scientific generosity. The company has been building toward competitive video generation, and their Hailuo product competes directly with Runway, Kling, and the various Sora-alikes. Video tokenization is even more challenging than image tokenization because temporal consistency matters. A tokenizer that genuinely understands semantics rather than just compressing pixels could provide meaningful advantages in that domain.
The MIT license is unusually permissive for a company of MiniMax's scale. They're clearly betting that open-sourcing the tokenizer creates ecosystem value that benefits their commercial products, even if competitors can use the same weights. It's the same playbook Meta ran with LLaMA, though applied to a narrower component.
What's missing
The paper doesn't address several obvious questions. How does VTP interact with different DiT architectures? The experiments use a specific configuration, but the field has moved toward varied approaches including flow matching and rectified flow. Does the semantic latent space help equally across all of these?
There's also no discussion of training data. The paper mentions large-scale pre-training but doesn't specify what corpus was used. Given that one of VTP's objectives is image-text contrastive learning, the choice of training data matters significantly. CLIP-style training is notoriously sensitive to the quality and diversity of caption data.
The comparison to concurrent work like GigaTok, which also tackles tokenizer scaling through semantic regularization, is limited to brief mentions. Both approaches seem to reach similar conclusions through different paths, suggesting the insight about semantic latent spaces is robust even if the specific implementation varies.



