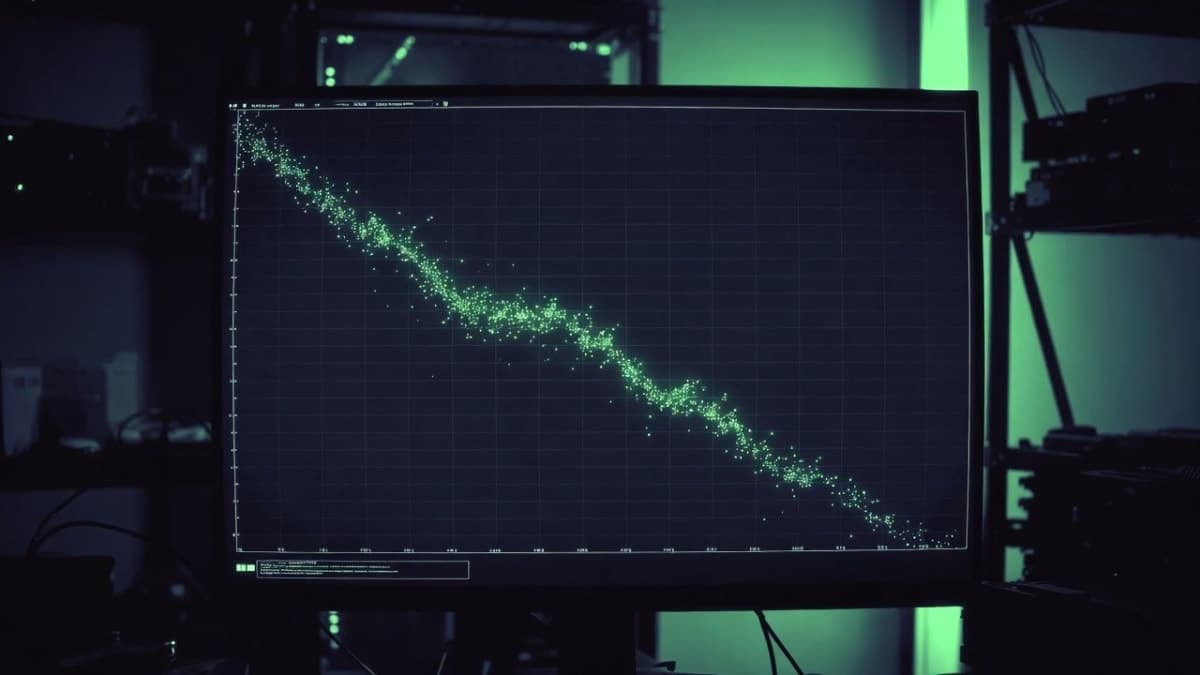
Andrej Karpathy released a new open-source project this week called autoresearch, and the pitch is simple enough to fit on a sticky note: point an AI agent at a training script, go to bed, wake up to a better neural network. Each dot in the progress chart he shared is a complete LLM training run, finished in exactly five minutes, with the agent deciding what to try next.
The GitHub repo is a stripped-down, single-GPU fork of his nanochat project, reduced to roughly 630 lines of training code. Three files matter: a data prep script the agent can't touch, a training script it can, and a markdown file that tells it what to do. That last one is where things get interesting.
The markdown is the research org
The real unit of work in autoresearch isn't Python. It is the program.md file, a set of instructions that functions as the agent's entire research strategy. The human iterates on this markdown doc. The agent iterates on the training code. Karpathy frames this as programming your "autonomous research org" rather than programming a neural network, and he's being only slightly tongue-in-cheek about it.
The agent works on a git feature branch, accumulating commits as it finds configurations that lower validation loss. Architecture, hyperparameters, optimizer settings, batch size, all of it is fair game. The metric is val_bpb (validation bits per byte), which stays comparable even when the agent changes the vocabulary size or model architecture between runs. That's a nice design choice, though it means your results aren't comparable to anyone else's unless you're on the same hardware.
And that's the trade-off Karpathy explicitly calls out. Fixed five-minute runs mean you get about 12 experiments per hour, roughly 100 overnight. But the optimal model the agent finds is optimal for your GPU. Someone on an H100 and someone on an A100 will end up in different places.
What the agent actually does
The training script contains a full GPT model implementation with a Muon + AdamW optimizer and the complete training loop. The agent modifies this file, runs the training, checks whether the validation loss improved, keeps or discards the change, and repeats. It's essentially a hill-climbing search over the space of training configurations, except the search operator is an LLM reading code and deciding what to change next.
There's no distributed training, no complex configs. One GPU, one file, one metric. Karpathy says the default program.md is intentionally bare-bones, a baseline for people to improve on. The implicit challenge: who can write the markdown that produces the fastest research progress?
He made this explicit in a follow-up post: "the real benchmark of interest is: what is the research org agent code that produces improvements on nanochat the fastest? this is the new meta."
Part code, part sci-fi
The README opens with a fictional vignette set in a future where AI agents have iterated through 10,205 generations of a self-modifying codebase that's grown beyond human comprehension. "This repo is the story of how it all began," Karpathy writes, dating it March 2026. He described the whole thing as "part code, part sci-fi, and a pinch of psychosis."
It's a joke. But it also isn't, entirely.
This lands in a moment when Karpathy himself has been pushing the vocabulary of AI-assisted development forward. He popularized the term "vibe coding" in early 2025, then moved on to coining "agentic engineering" to describe a more structured version of the same idea. Autoresearch feels like the logical next step: what happens when the agent isn't building your app but running your experiments?
The constraints worth noticing
The repo currently requires a single NVIDIA GPU (tested on H100). No CPU, no Apple Silicon, no AMD. Karpathy says he's not sure he wants to take on broader platform support himself, pointing people toward the full nanochat repo for that. He's also noncommittal about how much he'll maintain this going forward, calling it "just a demonstration."
That's worth flagging. The repo had about 1,800 stars and 200 forks within days of launch, but it's a weekend project with weekend-project caveats. The agent loop itself isn't in the repo; you bring your own (Claude, Codex, whatever). The program.md is the interface, and it's deliberately minimal.
There's also no mechanism for the agent to reason about why something worked. It's not writing up findings or building a theory of the loss landscape. It just tries things and checks the number. That's fine for hyperparameter sweeps and minor architectural tweaks, but I'm skeptical it discovers anything you'd write a paper about. The interesting question is whether a better program.md could change that, and Karpathy seems to think so.
Where this sits
Autoresearch isn't the first attempt at automated ML research. The broader idea of using AI to automate the ML research loop has been floating around for a while, from neural architecture search to more recent efforts like Sakana AI's "AI Scientist." But those tend to be complex multi-agent systems. Karpathy's version is aggressively simple: one file, one metric, one loop. The complexity lives in the markdown prompt, not the infrastructure.
The nanochat project it builds on has its own momentum. Karpathy and the community have been optimizing it to train a GPT-2 grade model faster and cheaper, currently down to about 2-3 hours on an 8xH100 node for under $100. Autoresearch takes just the pretraining core, simplifies it for a single GPU, and hands the optimization work to an agent.
Whether that agent can match a motivated human researcher over a weekend of tinkering, well, that's the experiment. Karpathy ran 110 agent-driven changes over about 12 hours on nanochat earlier this month, improving validation loss from 0.862 to 0.858 on a d12 model. A real improvement, but a small one. The slope of that progress curve, and whether it flattens or keeps going, is the thing to watch.