Andrej Karpathy released autoresearch on March 7, a stripped-down Python script that hands the tedious loop of ML experimentation to an AI agent. The agent edits a training script, runs a five-minute training pass on a single GPU, checks if validation loss improved, keeps or discards the change, and does it again. All night. Without you.
The pitch is almost too simple to take seriously. But then Karpathy left it running for two days on a depth-12 model, and the results were hard to ignore.
What the agent actually found
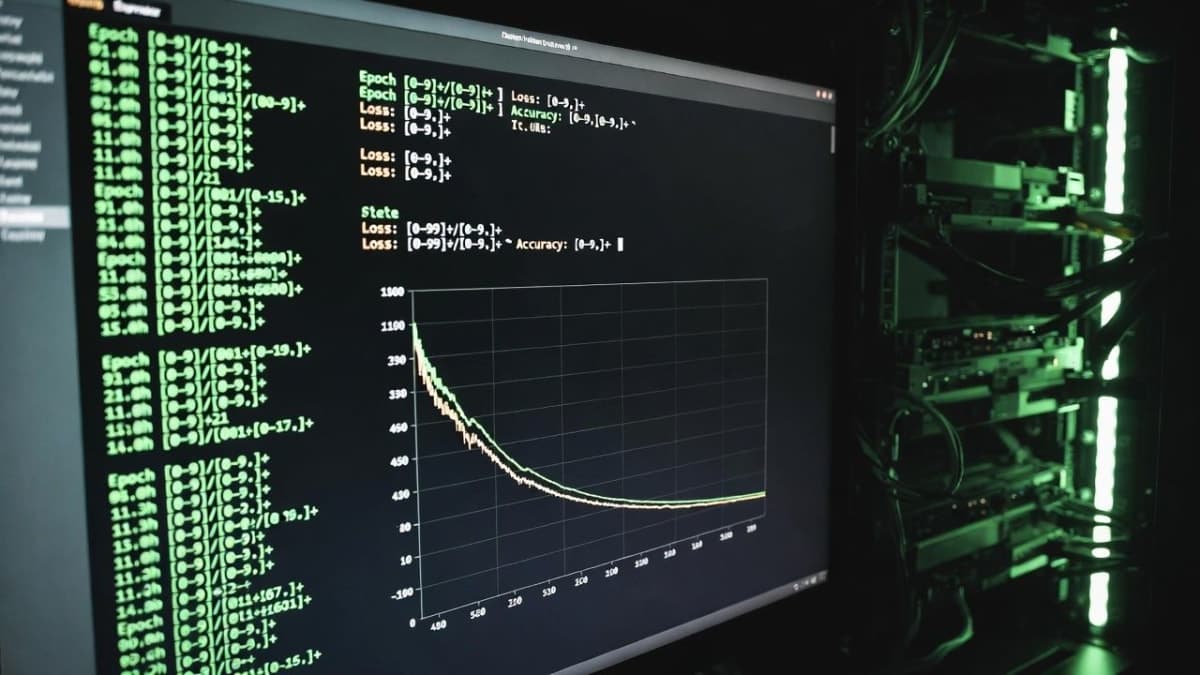
Over roughly 48 hours the agent churned through about 700 code edits. Most were garbage, discarded after the five-minute training window showed no improvement. Around 20 changes survived. All of them were additive, meaning they stacked without canceling each other out, and they transferred cleanly from the small depth-12 model to a larger depth-24 one.
Karpathy posted the specifics on X: the agent noticed his parameterless QKNorm was missing a scaler multiplier, leaving attention too diffuse. It found that Value Embeddings needed regularization he wasn't applying. It caught that his banded attention window was too conservative (he'd forgotten to tune it). It flagged messed-up AdamW betas. Weight decay schedule, network initialization, both got tightened.
"I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project," Karpathy wrote. He has two decades of hands-on neural network tuning experience. The agent caught oversights he'd been living with for months.
Stacking all 20 changes, the nanochat leaderboard's "Time to GPT-2" metric dropped from 2.02 hours to 1.80 hours. That's roughly 11%, and it landed as the fifth entry on the leaderboard, beating every previous entry Karpathy had submitted manually.
The design is the interesting part
Autoresearch is about 630 lines of code. Three files matter: prepare.py (data prep, frozen), train.py (the agent's playground), and program.md (your instructions to the agent, written in plain Markdown). The agent can modify train.py however it wants. It cannot touch the evaluation function. This separation is the whole trick.
Every experiment gets exactly five minutes of wall-clock training time regardless of what the agent changes. Model size, batch size, architecture, optimizer settings, whatever. Five minutes. This makes every run directly comparable and means you can expect about 12 experiments per hour, roughly 100 overnight. The metric is validation bits-per-byte (val_bpb), which is vocabulary-size-independent, so the agent can freely swap architectures without breaking the evaluation.
Git serves as the memory system. Improvements get committed to a feature branch. Failures get reset. The commit history becomes a lab notebook.
Here's what I find genuinely clever about this: the entire codebase fits inside the context window of a modern LLM. That's not an accident. It means the agent can hold the full training script in memory while reasoning about what to change. No retrieval-augmented generation, no complex tool chains. Just one file and one objective.
Shopify's CEO tried it before breakfast
Within a day of the release, Shopify CEO Tobi Lütke posted on X that he'd pointed autoresearch at QMD, his open-source local search tool. Before bed, he told an AI agent to read the autoresearch repo, build a version for QMD's query-expansion model, and pull training data from his GitHub. Eight hours later: 37 experiments, a 19% improvement in validation score, and a 0.8B parameter model that outperformed the previous 1.6B model it was replacing.
Lütke is not an ML researcher. He said as much. But he also said he learned more from reading the agent's reasoning through those 37 experiments than from months of following ML researchers on social media. Karpathy's response was characteristically dry: "Who knew early singularity could be this fun."
The Lütke result is a single overnight run by a non-specialist. Fair to question whether it generalizes. But a 0.8B model beating a 1.6B model just by letting an agent grind through hyperparameter space overnight? That's a concrete, verifiable claim, not a benchmark on a leaderboard nobody reads.
Now there's a swarm version
The original autoresearch is one agent, one GPU, one loop. Autoresearch@home, a fork coordinated by Christine Yip and Austin Baggio, adds a collaboration layer on top. Multiple agents running on different machines can claim experiments, publish results (successes and failures), and pull the current global best configuration. The coordination happens through a shared memory service called Ensue, and if the network goes down, agents fall back to solo mode.
The SETI@home comparison is obvious and deliberate. Instead of distributed protein folding or radio signal analysis, you're distributing ML experimentation. Each agent reads what others have tried, avoids duplicates, and builds on discoveries. The project launched on March 11 and is still accumulating experiments in real time.
Whether distributed agent swarms actually produce better results than a single well-prompted agent running longer is an open question. The coordination overhead isn't zero. Semantic similarity checking to avoid duplicate experiments, global state synchronization, hypothesis exchange, these add complexity that Karpathy's original deliberately avoided. But the appeal is obvious: more GPUs, more experiments per hour, potentially faster convergence.
What this doesn't tell us
Autoresearch optimizes a clean, single metric on a small model. Val_bpb goes down, that's good. The agent never has to make a judgment call about tradeoffs. It never has to decide whether latency matters more than accuracy, or whether a 2% quality gain justifies a 40% increase in inference cost. Real production ML is full of those decisions.
The 11% improvement on nanochat is real, but nanochat is a toy. (Karpathy would be the first to say so.) DeepSeek-V3 is 671B parameters. Does this approach scale? The Latent Space newsletter noted that agent loops remain fragile across different harnesses and models, with GPT-5.4 failing to follow a "LOOP FOREVER" instruction while Claude Opus 4.6 ran for 12+ hours and 118 experiments without breaking. The tooling isn't mature.
And there's the overfitting question. One researcher on X asked Karpathy directly whether running that many experiments would eventually spoil the validation set. It's a legitimate concern. Karpathy's answer, that they're optimizing performance per compute and the gains are real, doesn't fully address it.
The role shift
What autoresearch actually changes is the job description. You stop editing Python. You start editing a Markdown file that tells an agent how to think about editing Python. Karpathy has been inching toward this framing for a while. He popularized "vibe coding" and later proposed "agentic engineering," where you orchestrate agents instead of writing code directly. Autoresearch takes it one step further: you write the Markdown, the agent runs indefinitely, and you check the results when you wake up.
The leaderboard entry tells the story. A human researcher with 20 years of experience was beaten by his own agent running his own framework on his own model. The improvements were things he'd missed, not things he'd rejected. The agent didn't have better taste. It just had more patience.
Karpathy says he's kicking off round two, and looking at how multiple agents can collaborate to unlock parallelism. The nanochat leaderboard is public, the code is MIT-licensed, and anybody with a GPU can fork it. Whatever happens next will happen in the open.



