A team of researchers led by Xiwei Xu, Xuewu Gu, and Liming Zhu has released a paper proposing that AI systems manage their context the way Unix manages files. The work, published on arXiv this week, introduces a file-system abstraction for what the authors call "context engineering" and implements it in the open-source AIGNE framework.
The Problem: Context Rot
Large language models face a structural limitation that compounds as systems grow more complex. The models themselves are stateless: when a conversation ends, everything the AI learned during that exchange disappears. External memory systems exist, but they remain fragmented across different tools, producing what the researchers describe as "transient artefacts that limit traceability and accountability."
The paper identifies a specific failure mode called "context rot," where AI systems gradually lose coherence as memory entries accumulate, contradict each other, or become stale. Token windows (the amount of text an LLM can process at once) create hard ceilings: GPT-5's limit is 128,000 tokens, while Claude Sonnet 4.5 handles 200,000. When context exceeds these limits, something must be cut. Current systems make those cuts without systematic governance.
The Proposal: Mount Context Like a File System
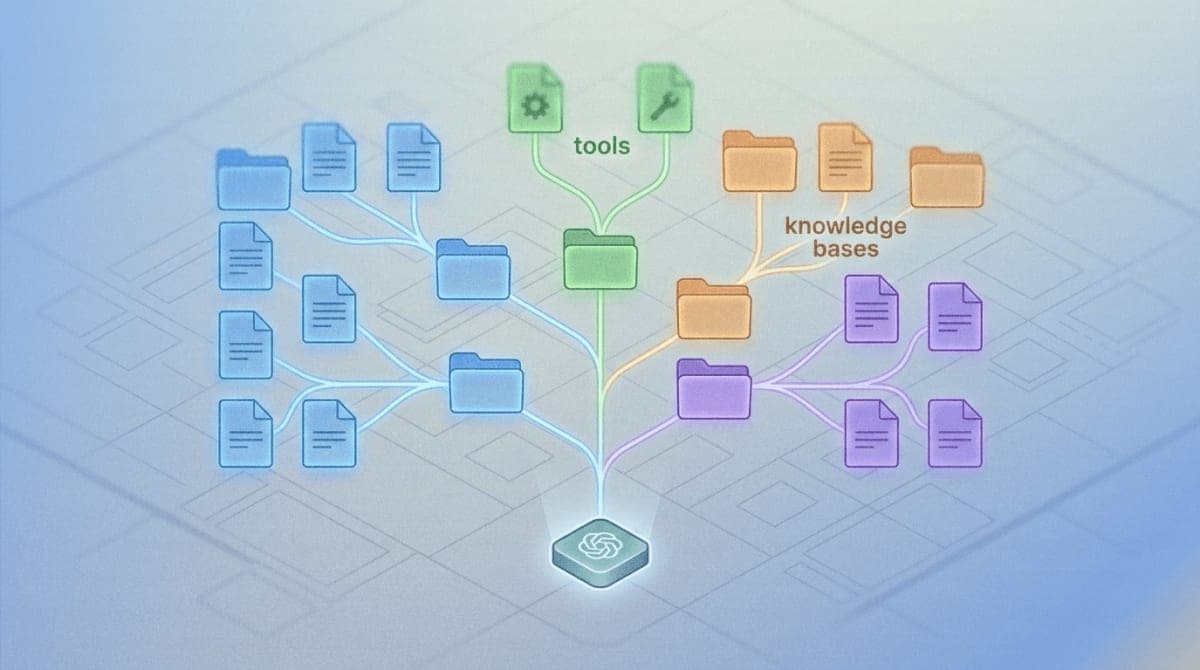
The researchers draw their central insight from the Unix operating system, which treats keyboards, disk drives, network connections, and actual files through a single abstraction: "everything is a file." The paper applies this principle to AI context.
Under the proposed architecture, different context sources (conversation history, tool definitions, user profiles, external knowledge bases) are "mounted" into a unified namespace. An AI agent accesses a GitHub repository the same way it accesses a memory store or a user preference file, through standard read, write, and search operations on paths like /context/memory/ or /modules/github-mcp/.
The file-system metaphor brings specific engineering benefits. Context elements gain metadata (timestamps, provenance, version IDs). Changes become auditable through transaction logs. Access controls can restrict which agents see which context. Different storage backends (vector databases, SQL, knowledge graphs) slot in as plugins without requiring changes to the agents that use them.
The Pipeline: Constructor, Updater, Evaluator
Built on top of the file-system layer, the researchers describe a three-stage pipeline for managing context throughout an AI reasoning session.
The Context Constructor selects and compresses relevant information from the persistent repository to fit within token constraints. It generates a "manifest" documenting what was included, what was excluded, and why. This addresses a common opacity problem: when an AI fails to recall something, operators typically cannot determine whether the information was never stored, was stored but not retrieved, or was retrieved but compressed away.
The Context Updater handles the transition from storage to active reasoning. For short tasks, it loads a static snapshot. For ongoing conversations, it streams context incrementally, replacing stale fragments as the dialogue progresses.
The Context Evaluator closes the loop by validating outputs against source context, detecting contradictions or hallucinations, and writing verified information back to persistent storage. When confidence drops below threshold, it flags content for human review rather than committing it automatically.
Implementation: The AIGNE Framework
The architecture is implemented in AIGNE (available on GitHub at github.com/AIGNE-io/aigne-framework), a TypeScript/JavaScript framework for building AI agents. The framework integrates with OpenAI, Google Gemini, Anthropic Claude, DeepSeek, and Ollama models.
The paper provides two working examples. The first shows an agent with persistent memory stored in SQLite, where conversation history survives across sessions without manual state management. The second demonstrates mounting a Model Context Protocol (MCP) server, in this case GitHub's official MCP implementation, as a file-system module. The agent interacts with GitHub repositories through the same afs_read and afs_exec operations it uses for local files.
What This Enables
The file-system approach makes AI context compatible with existing DevOps practices. Context can be versioned, reviewed in pull requests, and deployed through CI/CD pipelines. The authors note that this moves context management "from ad hoc prompt management" to systematic engineering.
For multi-agent systems, the architecture provides resource isolation. Different agents can mount different views of shared context, with access controls preventing cross-contamination. The unified namespace also allows agents to discover available tools and data sources dynamically rather than having tool definitions hard-coded into prompts.
The research team plans to extend the work with "agentic navigation," allowing AI systems to autonomously browse and organize their own context hierarchies. They also intend to strengthen what they call "human-AI co-work," positioning humans not just as supervisors who correct errors but as active participants who contribute and curate knowledge alongside AI agents.
The AIGNE framework is available under open-source license. The full paper, "Everything is Context: Agentic File System Abstraction for Context Engineering," is accessible on arXiv as paper 2512.05470.



