Researchers at the Chinese Academy of Sciences have identified a counterintuitive problem in AI-generated image detection: training detectors on images from more generators initially helps, then actively hurts performance. Their solution, published on arXiv in December, achieved 90.4% accuracy across six benchmarks covering over 4,700 different image generators.
The finding upends the conventional wisdom that more diverse training data leads to better generalization. For fake image detection, the opposite appears to be true past a certain threshold.
The paradox nobody expected
The intuition seems sound: if you want a detector that catches images from any generator, train it on images from many generators. The research team calls this "train on one to train on many." It's how most current approaches work.
What actually happens is more complicated. Using Linear Discriminant Analysis to measure how separable real and fake images remain in feature space, the researchers tracked detector performance as they added generators to the training set. With one generator, feature separation was clean. With two, still fine. At four, performance peaked. By eight, it started declining. With thousands of generators, the features became nearly inseparable.
The team calls this the "benefit then conflict" phenomenon. Their mathematical analysis suggests why: each additional generator adds variance to the generated image distribution, while real images maintain consistent variance. Eventually the generated distribution becomes so heterogeneous that it overlaps with the real distribution entirely.
Why CLIP makes things worse
Most recent AI image detectors rely on frozen CLIP encoders as their backbone. The logic is reasonable: CLIP's pretrained features provide strong semantic understanding without overfitting to specific generators. Papers from CVPR and ICLR in recent years have built increasingly sophisticated classification heads on top of frozen CLIP.
The researchers found this creates a fundamental ceiling on performance. When you freeze the encoder, you're forcing the model to separate real from fake using only the features CLIP was trained to extract, which were optimized for image-text matching, not forgery detection.
In their experiments, end-to-end trained models consistently showed higher Fisher ratios (a measure of class separability) than frozen-encoder approaches on the same data. The gap widened as generator diversity increased. CLIP's semantic priors, useful when training on a single source, become contradictory when learning from thousands of heterogeneous generators.
The visualization is striking. With one generator (ProGAN), CLIP embeddings show real and fake images in clearly separated clusters. With thousands of generators, the clusters overlap almost completely.
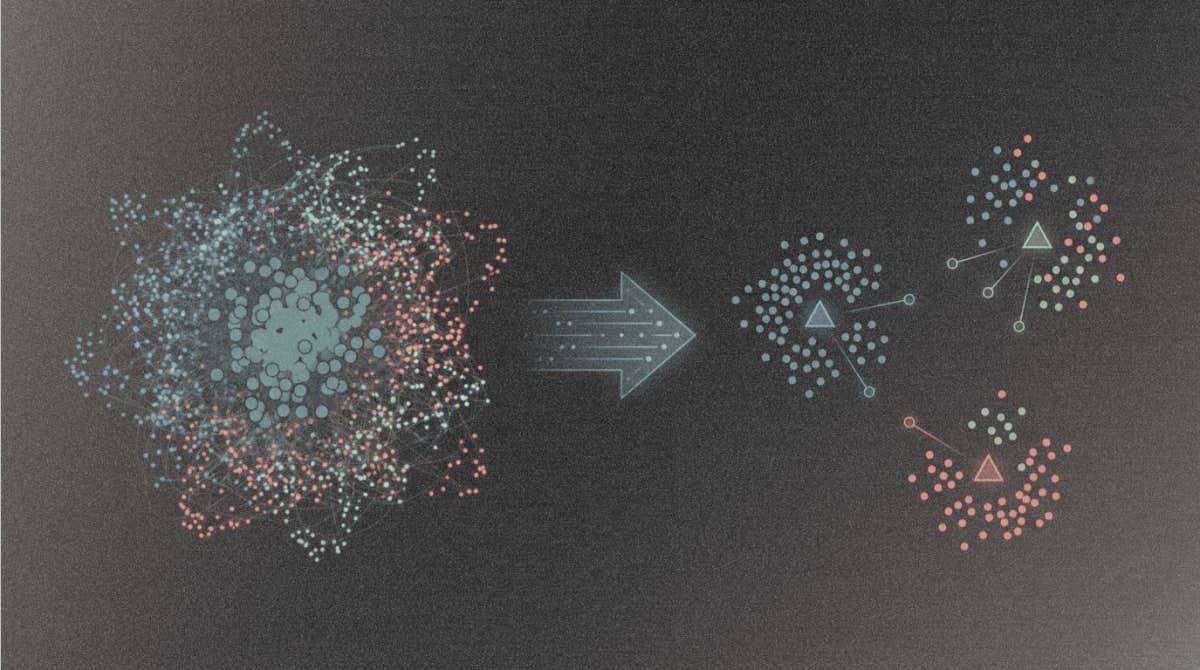
Turning thousands into a few
The proposed solution, Generator-Aware Prototype Learning (GAPL), works by compressing the heterogeneity rather than trying to model all of it. The approach learns a small set of "forgery prototypes" from just three canonical generators: ProGAN (representing GANs), Stable Diffusion v1.4 (representing latent diffusion), and Midjourney (representing commercial APIs).
The training happens in two stages. First, an MLP learns to distinguish real from fake on just these three generators, creating a forgery-related feature space. The team then extracts the top principal components from this space as prototypes. Second, they fine-tune the CLIP encoder using LoRA (Low-Rank Adaptation) while mapping all images to this prototype space via cross-attention.
The math behind prototype mapping sets an upper bound on feature variance regardless of how many generators appear in training. If the prototypes span a space of maximum diameter D, the variance of mapped features can't exceed D²/4. Generator diversity stops mattering.
The researchers trained their final model on Community Forensics, a dataset with 4,700+ generators, but used only 550,000 images rather than the full 5.4 million. Despite the smaller training set, GAPL outperformed detectors trained on the complete dataset.
What the benchmarks show
Across six test sets covering GANs, diffusion models, and commercial APIs, GAPL achieved 90.4% mean accuracy and 94.9% mean average precision. The improvement over the next-best method (Community Forensics at 86.9%) is 3.5 percentage points.
More interesting than the overall numbers is where GAPL wins. On SynthBuster, a benchmark specifically designed to avoid format shortcuts (all images are PNG), GAPL hit 91.1% while several specialized detectors hovered around 50%, essentially random chance. On Chameleon, a dataset of images explicitly selected to be indistinguishable by humans, GAPL managed 71%, compared to 65.8% for the previous best scaling-up approach.
The robustness tests are the real story for practical deployment. When images are JPEG compressed at quality factor 60, frequency-based detectors like SAFE and AIDE collapse to near-random performance. GAPL degrades by only 11%. Similar patterns hold for Gaussian blur.
What the prototypes actually learn
The researchers visualized which prototypes activate for which images. Certain patterns emerged consistently: distorted lines and unrealistic geometry triggered one prototype, over-smooth material surfaces another. For real images, complex natural scenes and consistent portrait lighting activated specific prototypes.
This suggests the model isn't just memorizing generator fingerprints. It's learning something closer to a taxonomy of visual artifacts. Whether that generalizes to fundamentally new generation techniques, the authors acknowledge they cannot yet assess.
The frozen encoder problem won't go away
The paper's critique of frozen CLIP extends beyond this specific task. The broader implication: as AI-generated content becomes more diverse, approaches that rely on fixed pretrained features may systematically underperform methods that adapt the encoder to the detection task.
Current state-of-the-art detectors, including several presented at CVPR 2025, still use frozen encoders. The GAPL results suggest this design choice may be fundamentally limiting. LoRA provides a middle path, preserving most pretrained knowledge while allowing task-specific adaptation, but the field hasn't widely adopted it for image forensics yet.
The code is available on GitHub. The training requires only two RTX 4090 GPUs, modest by current standards. Whether the prototype approach scales to whatever comes after diffusion models remains an open question the authors explicitly flag as a limitation.



